福岡市地下鉄七隈線開業祝いと、天神・天神南間乗り換え制度廃止に関する考察
祝辞
3月27日(月)、福岡市地下鉄七隈線の天神南~博多間が延伸開業しました。福岡市城南区周辺の利便性が増し、さらに天神地区と博多駅地区の高速な交通手段が増えたことは大変素晴らしいことです。近々延伸開業区間を利用しに行ってみようと思います。
この記事の要旨
祝ってばかりもいられない事態に対するもそもそとした苦言です。
地下鉄七隈線延伸とともに施行された、天神・天神南間乗り換え制度廃止は、
- 乗り換え制度継続のための、福岡市交通局の運賃(料金)制度再設計の当初案に問題があった。
- その問題は、利用客の利益や運賃制度の趣旨に反する「短い距離の経路を利用していると特定できている状況にもかかわらず、長い距離の経路を利用していると見なされ、実際の乗車距離よりも高い運賃を払わされる」事態が生じかねないものとなっていた。
- 国からの問題指摘に対し、制度継続の方向性で補正しきれなかった(あるいは何らかの別の問題で補正しなかった)のではないか。
との私の見解を、そこに至る過程と資料とともに長々と説明します。付随する問題として、
- 国からの指摘事項「乗車距離に応じた運賃収受」の指摘内容の本質に誤解があった可能性。
- 福岡市交通局はNHKや西日本新聞の取材に対し、市議会へ報告した資料の一部の説明(国からの指摘の最も重要な本質であったと思われる点)を(意図的ではないと思われるが)欠いた。
というのも挙げます。
延伸の影で起きた問題:空港線天神・七隈線天神南間乗り換え時運賃通算制度の廃止
この影で実施された、ひとつの運賃制度変更があります。それが空港線天神駅と七隈線天神南駅との間で乗り換える際に、乗り換えのために一方の改札を出場した後120分以内であれば、乗車駅から降車駅までの営業キロを通算して運賃を算出する(改札の出入りに伴う初乗り運賃の収受をしない)制度の廃止でした。この件は交通局ウェブサイトや各駅に掲示され、地元メディア(NHK福岡・西日本新聞)による取材報道があった他、それ以外の各局でも周知が行われました。駅ポスター掲示時は、周知したい内容の趣旨が肝心の利用客にあまり伝わっていない(現行の運賃制度に関する一定の知識がなければ、告知内容の意味するところを十分に読み取れない)ような印象がありましたが、報道により多くの人が制度変更の内容を正しく知るところとなりました。各メディアのウェブサイト掲載記事は以下の通りです。
改札を一旦出ての同一事業者路線の乗り換えを要請する事例は全国に複数あり、同じ地下鉄の場合だと、東京地下鉄(東京メトロ)や大阪市高速電気軌道(Osaka Metro)に見られます。いずれの場合も、一定の時間内で改札を出入りする場合は、乗り換えの前後で営業キロを通算し、一旦改札を出ることによって生じる不利益を最小限にするよう制度が設計されています。乗り換え時間設定は東京メトロですと各指定駅間において60分、Osaka Metroでは梅田3駅(御堂筋線梅田・谷町線東梅田・四つ橋線西梅田)のみこの事例があり、30分で設定されていました。一方、福岡市交通局は120分以内という破格の設定をしていました。天神駅と天神南駅は天神地下街を介して約500m離れているため、乗り換え利用の利便性は決して良いものではなく、日常的に乗り換え利用をする人からは長い距離を歩かされることへの不満がたびたび聞かれていました。しかしながら、乗り換えの途上で120分もの時間を利用できるため、数多く立地する商業施設に立ち寄りつつ、1回分の運賃で行き来するような利用が可能でしたし、おそらくそうした立ち寄り需要を想定した時間設定であったと推測されます。
今回の七隈線博多延伸により、七隈線と空港線は博多駅で改札内接続となり、改札を出ずとも両路線間を行き来できるようになりました。とはいえ、空港線赤坂以西(姪浜方面、JR筑肥線筑前前原・唐津方面)と七隈線相互間利用や、箱崎線と七隈線の相互間利用の場合は、博多駅を通ると遠回りとなります。空港線博多駅と七隈線博多駅が離れていることもあり、どうせ乗り換えで遠回りしたり歩いたりするなら、天神と天神南の間でも引き続き乗り換え利用ができたら便利です。そのまましておけばみんなハッピーです。しかし、乗り換え制度は廃止されました。
乗り換え制度廃止に至った経緯の説明の整理
本件については福岡市議会の2021年(令和3年)2月19日・生活環境委員会第1回定例会における交通局からの報告資料「地下鉄七隈線延伸区間開業に伴う料金制度について」として公開され、閲覧が可能です。
NHK福岡、および西日本新聞の取材に対して、福岡市は「二重料金の混乱」と「公平性」を挙げています。
「二重料金」とは
福岡市交通局は運賃(交通局においては「料金」と呼称)を、乗車距離に応じた区間数により設定・収受します。専門用語では「対キロ区間制」と呼ばれる方式の運賃設定となっています。運賃表(料金表)は公式ウェブサイトと各駅に示され、各駅間距離表や料金区分表が三角表形式で公式ウェブサイトに公開されています。
本件のそもそもの発端は、空港線・箱崎線と七隈線相互間を利用する際に、天神・天神南乗り換えと博多乗り換えの2経路が並存した場合に、経路により運賃計算の根拠となる距離が異なる事態が発生したことにあります。これは福岡市交通局としては初のケースですが、他の鉄道事業者では遠い昔から数多くの場所で発生しており、現在も存在し続けています*1。その距離の変化が短くなる方だけでしたら誰も文句は言いません。しかし、2ルートあればどちらかが近道、どちらかが遠回りになります。遠回りになっても運賃が変わらなければこれまた誰も(運賃面については)文句は言いません。でも、対キロ区間制運賃の運賃区界の距離をまたぐ事態は確実に発生するため、そこに該当すると高くなってしまいます。経路が違う場合に原則通りの運賃を算出すると、経路により2つの異なる運賃が算出されてしまいます。これを福岡市交通局は「二重料金の問題」と称しました。
他の事業者ではどのように対処しているかと言うと、一般には長距離路線を有する事業者では乗車経路通りの乗車券を購入するよう要請し、比較的小規模の路線の事業者ではどのような経路で乗ろうとも、最短距離の経路で乗車したと見なして運賃を収受するような制度になっていることが多いです。長距離路線であっても、特定の区間ではどのルートで乗ろうとも最短距離で計算するよう取り計らったり、事業者の都合で利用客にとって本来不要な遠回りを強いる時は、その遠回り分の運賃を収受しない規則が別途制定されています。最近では、交通系ICカードの普及により、ICカード利用時はある程度長距離の利用でも(中間改札がなければ途中の経路を特定できないシステムの都合上)最短経路で収受する規則が制定されたりしています。
つまり総じて言えば利用客の不利益とならないように、対応する規則や運賃収受システムが各社それぞれ確立しています。端的に言えば、福岡市交通局がそれらの事業者のどちらかの制度に倣えば「二重料金の問題」はただちに解消され、国からも容易に認可を受けることができます。
ちなみに、福岡市交通局は天神・天神南乗り換えを残しつつ( = 2つの経路が存在する状態としつつ)、定期乗車券については経由指定の乗車距離通り、普通乗車券やICカード利用の場合は「経由地によって乗車距離が異なる場合であっても同一料金とする」案を作成し、国と協議したとのことです。
「(他の事業者に事例がごまんとあるし)そう(乗り換え制度廃止に)はならんやろ」「(廃止に)なっとるやろがい!!」(by『ポプテピピック』)
廃止になったということは、つまり福岡市交通局が天神・天神南乗り換えを残しつつ作成提出した運賃制度改正案が、国からの認可を受けられなかったということです。西日本新聞の上記記事においては、このことを
当初は市も残す方針だった。ルートを問わず、乗り降りする駅で運賃を設定する計画にしていたが、「乗った距離に応じて運賃を決める」という国のルールが待ったを掛けた。
と記載しています。
こういう場合「せっかく便利なままにしてくれようとしたのを、国のお役所仕事で蹴ったんだろ」と思われることが多いと思いますし、この問題が最初に出てきた2年前かそのあたりには、私もそう思っていました。でもちょこちょこと調べた結果、なんか事情が違うのではないかとの見解を持つに至りました。このあたりから細かい話が延々と続きますがご容赦ください。
鉄道における運賃の定め方
では、「乗った距離に応じて運賃を決める」という国のルールとは何でしょう。これは説明の不足があります。厳密には「距離に応じて運賃を決めよ」とは関係する法令のどこにも書いてありません。福岡市交通局における問題を正しく説明するなら、「福岡市交通局が国に届け出て認可を受けた運賃設定の上限額、および、その上限を超えない範囲での運賃の設定方法として届け出た方式(対キロ区間制)により、適切に運賃を定めよ」というルールになります。
運賃に関する事項は、鉄道事業法*2第16条、および鉄道事業法施行規則*3第32条および第33条に定められています。これらの条文が要請する運賃制定の手続は、
- 運賃の上限を定めて認可を受けよ。
- その上限は、適正な原価と適正な利潤によって決めよ。また、根拠となる計算資料(原価計算書)等を示すこと。
- 運賃の適用方法(収受する運賃の算出方法)を決めて届け出よ。
- 期間や区間を限って特別な運賃を設定する場合は、適用条件を決めて届け出よ。
です。この条件を満たし、かつ妥当である旨を説明できるものであれば、認められます。実際、乗った距離によらない運賃設定をしている事業者は数多くあります。その一例が均一制運賃です。どのような距離乗ろうとも、1回乗車について一定の額を収受するものです。路面電車を中心に見られ、九州では長崎電気軌道が大人140円・小児70円(指定停留所での乗り換え制度を設定)、熊本市交通局(熊本市電)が大人170円・小児90円、鹿児島市交通局(鹿児島市電)が大人170円・小児80円となっています。この制度は(妥当な理由さえあれば)地下鉄だろうと長距離を走る鉄道だろうと適用することは可能です。
福岡市交通局の当初案と問題
国(今回は国土交通省)が指摘するということは、そこに何らかの問題があることを示します。また、行政は一貫性のある取り扱いを尊重するため、よほどの理由がなければ前例を踏襲することを選択しますし、その例に類似する変更、その例に則った変更については審査が進みやすくなります。先に示した交通局からの報告資料では、天神・天神南乗換を残しつつ、運賃を1通りに定めるために次のような方式で運賃を定めるよう案を作成したとの説明が記載されていました。
- 定期乗車券については、利用客が購入時に選択した経路に従って運賃を算出する。
- 普通乗車券・ICカード乗車券による利用時
運賃制度に詳しい鉄道ファンや、同業他社の人であれば「おや?」と思うところがあると思います。上記赤太字で示した部分を含む条項は、他社ではなかなか見ない表現です。単に最短距離で計算すると書けば良いのではないかと思われるはずです。これではどこかの区間でこの条項によって計算したら、乗った距離にもかかわらず高い運賃を取られるのではないか。その事例は当の報告資料に図入りで書かれていました。
大濠公園~福岡空港間(両駅はともに空港線に所属)を利用する場合、空港線のみを経由する場合は距離7.7km(3区・300円)ですが、七隈線延伸開業により、運賃計算上同一駅とみなされる天神・天神南乗り換えを選択して七隈線櫛田神社前を経由するルートが最短経路となり、距離6.8km(2区・260円)と算出されます。しかし、上記運賃計算基準により、たとえ距離の短い七隈線櫛田神社前経由を利用したとしても、全区間空港線経由とみなされて高い運賃を取られることになります。どの経路を選んだか分からないのであれば、最短経路計算にならないことによる利用客からの不満が出るにせよ、理解を求めることが可能です。しかし、この事例ですと、七隈線櫛田神社前経由の利用を選択した場合に、天神駅の改札と天神南駅の改札をともに通過することから、距離が短い方の経路を通ったことが明らかなのに、長い方の経路を通ったことにされて本来よりも高い運賃を取り立てられてしまうことになる、という致命的な不具合が存在したことになります。
報告資料にある国からの指摘事項は、
- 福岡市交通局が提出した改正案では、法令に定める手続により認可した、現在の上限運賃を超えるような事例が発生するため、上限運賃変更認可申請を要する可能性がある。
- 経路の特定ができるにも関わらず距離に応じた運賃としていない。
- 普通券と定期券の取り扱いに差を設けている。
とされていました。1番については案策定の段階で、考え得る経路の調査もれがあったという、あまりよろしくない事態の可能性を示唆するものの、これは上限運賃の範囲内に収めるよう努力すれば認可申請は不要です。2番の条項ですが、多くの人(特に鉄道ファン)は、「高い方の経路で乗っていると分かっているなら高い方をきちんと取れ」と言っていると受け止めると思われますが、これは「利用客の利便と負担感を抑えるための特定運賃ウンヌンカンヌン」と主張し、JR東日本の首都圏エリアやJR西日本のアーバンネットワークエリアで多く見られる特定運賃の事例を引けば理解を求めることが可能と考えられます。つまり、今回は何をどう引っくり返そうとも利用客を説得可能な妥当な説明をつけることが不可能で、明らかに利用客に不利益を強いるような、「安い方の経路で乗っていると分かっているのになんで高い方の経路の運賃を取り立てるのか」という点を突っ込まれたのではないかと推測しています。3番についてはこれも利便性を盾に主張をすれば国も頑強になって蹴ることはないと考えられます。
公平性とは
この指摘を受けて福岡市交通局は改正案を作り直し、国土交通省の認可を受けたことで施行されたわけですが、その作り直しの際に考慮したというのが「公平性」と説明されています。この点については、NHK福岡と西日本新聞でともに示されている方の「公平性」は「経路による二重運賃の発生」ということでしたが、もう1点、NHK福岡の記事の方にのみ説明が存在する、もうひとつの「公平性」でした。その公平性は、NHK福岡が提起した「すべて最短経路の運賃とすれば良いのではないか?」との問いに答える形となっており、その趣旨は「実際には同じ距離を乗っているのに、最短経路計算特例により運賃に差が生じるのは公平性に欠けると判断した」となっていました。これはもっともらしく聞こえるものの、日本国内で多く施行されている鉄道運賃の規則の観点からすれば不可解な主張となっています。また、西日本新聞の記事にある「ルートを問わず乗り降りする駅で運賃を設定する計画にしていた」という姿勢と矛盾し、この点で整合性を取る説明をすると「制度再設計にあたって『同じ距離であれば同じ運賃を収受しなければならない』との原則を厳しく貫徹するよう方針転換があった」と解釈するほかありません。
最短経路計算に密接に関連する事例として、同じ距離を乗っているのに最安経路で運賃を計算する取り扱いが行われるため、運賃に差が生じる例・JRの「大都市近郊区間」の規定があります。これ自体は最安運賃で計算する旨を定めた規定ではありませんが、現場での実務上の取り扱いでは、乗車経路にかかわらず最安運賃の乗車券を発売したり、ICカード乗車券における運賃精算額を決定したりするよう処理しています。この大都市近郊区間では、同じ100kmの距離を利用しても、別の最安経路があるか無いかで大きく運賃に差が生じることがあります。JR九州管内ですと「福岡近郊区間」内で完結する利用の場合、代表的な例が鹿児島本線折尾以東、原田以南を発着する形で利用する場合に、実際には鹿児島本線博多経由であっても、運賃計算上、距離が短くなる筑豊本線直方経由で計算する場合があります。また、大都市近郊区間がかかわらない区間では、一部特例(経路特定区間・分岐駅通過にかかる区間外乗車の規定など)を除き、乗車経路通りの距離をもって運賃が定められるため、大都市近郊区間か否かによっても、同じ距離の利用に対する運賃に違いが出てくる事例も生じます。
また、JRの東京(JR東日本)・大阪(JR西日本)・名古屋(JR東海)の例では、並行する私鉄との競争力確保の一環として、特定の駅間の利用に対して距離の基準による算出とは異なる安い運賃を「特定運賃」として定めています。大都市でなくとも、対キロ区間制を採用している路線において、区界またがりにおける運賃の急上昇を避けるために特定運賃を設定している区間があります。近くの例ですと、西鉄天神大牟田線の三沢~小郡間は営業キロ3.1kmで、本来の規則による運賃はキロ程切り上げにより4km以上6km未満の区分となり、大人210円、小児110円となるところ、特定運賃として1つ下の運賃区分(初乗り)である大人170円・小児90円を定めています。
これらのことを総じて言えば、「妥当な理由を(国に)提示できれば、同じ距離の乗車でも異なる運賃となることが認められる」わけです。七隈線の事例であれば「事業者側の都合により遠回りさせられて、今までよりも運賃が高くなる事態を避けるため」と主張すれば通ったものと思われますので、距離に応じた運賃とすべしとガチガチになることはありません。
取られた解決策
最終的には、天神・天神南間の乗り換え制度を廃止し、空港線と七隈線の結節点を博多に限定した上で、当然この場合は経路は常に1通りに定まることから、その経路通りに運賃を定めることとなりました。たとえるならば「悪い公平性」をもって事態を片付けてしまったと私は評します。
本来実施するべきであったと私が考える策
他社の事例に鑑み、私は次の策を提示します。とはいえオリジナル要素はなく、基本的には東京メトロ、Osaka Metro等で施行されているものと全く同等のものです。
- 実際の乗車経路(距離)にかかわらず、最短経路(最安経路)で計算する。
- 天神駅・天神南駅での乗り換え出場の場合は、そこまでの最安経路の運賃を一旦収受する。120分以内であれば運賃計算を打ち切らず、改めて初乗り運賃を収受しない。
- 最終的な下車駅で、乗車駅と下車駅の最短経路運賃と、一旦収受した運賃とを比較する。不足があれば不足額を収受し、過剰の場合は返還しない。
3番の規則の「過剰の場合は返還しない」が他事業者で採用されている理由は、乗り換え駅を本来の目的地として往復する利用客より、乗り換え駅での乗り換え時間内に用を済ませ、より安くなる駅まで行って戻ってくる「余分な行動」をした利用客の方が運賃負担が安くなる事態を避けるためなのではないかと推測しています。福岡市交通局で同様の事例が発生するかどうかは検証を要します。もし事例がなければこの部分は不要です。これにより、福岡市交通局においても矛盾なく最安経路による運賃(最終着駅判定においては、過剰額返還がないため最安に「近い」運賃)とできるのではないかと考えています。
蛇足の憶測:福岡市交通局が不可解な当初案を作成した理由
この項目は完全なる私の憶測ですが、福岡市交通局の当初案は、運賃計算にかかる情報システムを構築する上では非常に楽なものが実現できます。新たに追加すべき経路計算をするための条件分岐が「発駅と着駅が『空港線・箱崎線』と『七隈線』にまたがっているか」の1つだけですので、常に最短経路を計算する場合と異なり、空港線・箱崎線各駅相互間発着となる場合に天神・天神南改札通過状況を検出判定するコードやデータを追加することなく、従来の計算ロジックと距離データがそのまま使える利点があったのではないかと思われます。
結果として、その条件による運賃計算では利用客の不利益につながる問題が生じると判明して制度自体の再設計を迫られたわけですが、そこで東京メトロ・Osaka Metro案を採らなかったあたりに、何か説明されていない事項の存在が疑われます。単にシステム再設計と改修の費用が予算化できなかったのか、その案を採用することによる別の不利益が存在したのか、国の担当者を説得し損ねたのか、これ以上は詳しい調査をしなければ分かりません。
*1:鉄道は大規模なネットワークを構成するので当然と言えば当然ですが。
文字だけで扱うコンピュータの世界(13.5):PowerShellへの簡単な寄り道
生きています
博士論文をガラクタから見てくれのいいガラクタへ変換するのに長い歳月を要し、さらにその中身をキラキラに見せるためのセールストーク作りにさらに長い歳月をかけ、ついにその日が週明けに迫りました。生きて帰ってきます。
ここまでの内容を忘れてしまったついでに寄り道
前回のこのテーマでの更新からすでに1か月半が経ち、もはや何をしていたか忘れました……というのは嘘です。記事を読んだら思い出しました。前回はついにPythonを持ち出していろいろ始めましたが、その記事でも述べた通り、Pythonのプログラム開発環境・実行環境を整えるのは結構面倒です。同じことを手軽にできたら便利ですよね? 便利でしょう?(圧力)
みなさんはWindowsパソコンをお使いだと思います。……Mac? 私は実は正統なるUNIXであるmacOSのことをそこそこ気に入っていますので、そちらのシェルを使った技を披瀝して高笑いしたいのですが、そちらは後の回にまわします。Windowsには、PowerShellというアプリケーションプログラムがデフォルトでインストールされています。PowerShellを利用すると、コマンドを打つことでWindowsのさまざまな情報を得たり、Windowsにインストールされているプログラムを実行したりできます。さらに、PowerShellの文法に基づいてプログラムを記述し、実行することもできます。
実は私もPowerShellのクソ分厚い解説書こそ1冊持っているものの、まともに運用したことがありませんでした。ですので、この機会にいろいろ調べながら小技集を展開します。
そもそものPowerShellの開き方
ここで、実は環境によって開かれるウィンドウが違ってきたりするので、少々頭が痛くなります。ここでは、PowerShellやターミナル関係の環境構築を一切していない場合で説明します。もしこのパターン以外でしたら、おそらく貴方はそれなりに "パソコンをプログラミング向けに使いこなせている" はずですので、がんばってたどり着いてください。
開き方1:スタートメニューから
スタートボタン(画面左下の窓っぽいボタン)をクリックし、その状態でキーボードから「powershell」と打つと、次のような結果が出てくると思います(Windows 11の場合。Windows 10でもわりとそっくりの表示になるはずです)。この中から「Windows PowerShell」をクリックするか、その画面でエンターキーを押してください。すると、次のような画面が開きます。
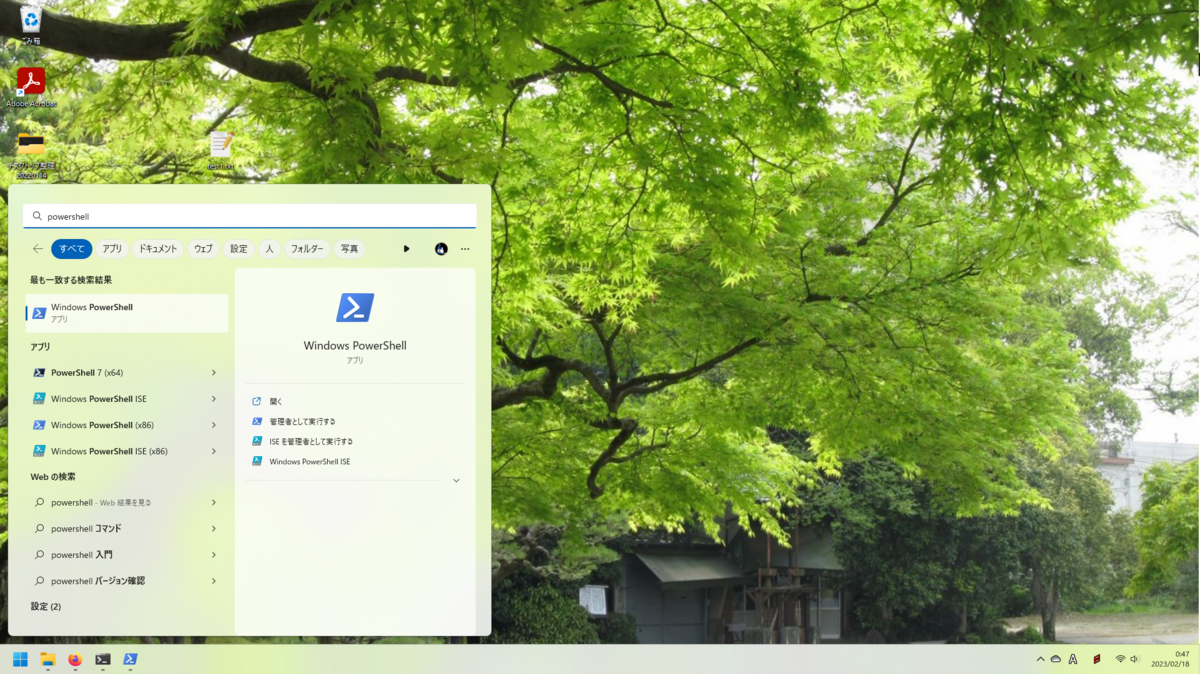

ここにコマンドを打ち込んだりすると、いろいろと結果が出ます。この開き方をした場合は、後でいろいろ扱うファイルを置いているフォルダ(ディレクトリ)に移動(操作対象を変更)する必要があります。
開き方2:対象フォルダ(ディレクトリ)に移動した状態で開く
たとえば、デスクトップが操作対象となっている状態で開きたい場合は、デスクトップ画面でShiftキーを押しながら右クリックしてください。次のようなメニューが出てきます。私の環境では右クリックメニューを最初から全部展開するよう設定を変えているのと、いろいろ入れまくっているのとでごつい見た目になっています。Windows 11のデフォルトの右クリックメニューの場合は、出てきたメニューから「その他のオプション」をクリックすると同じメニューが出てきます。
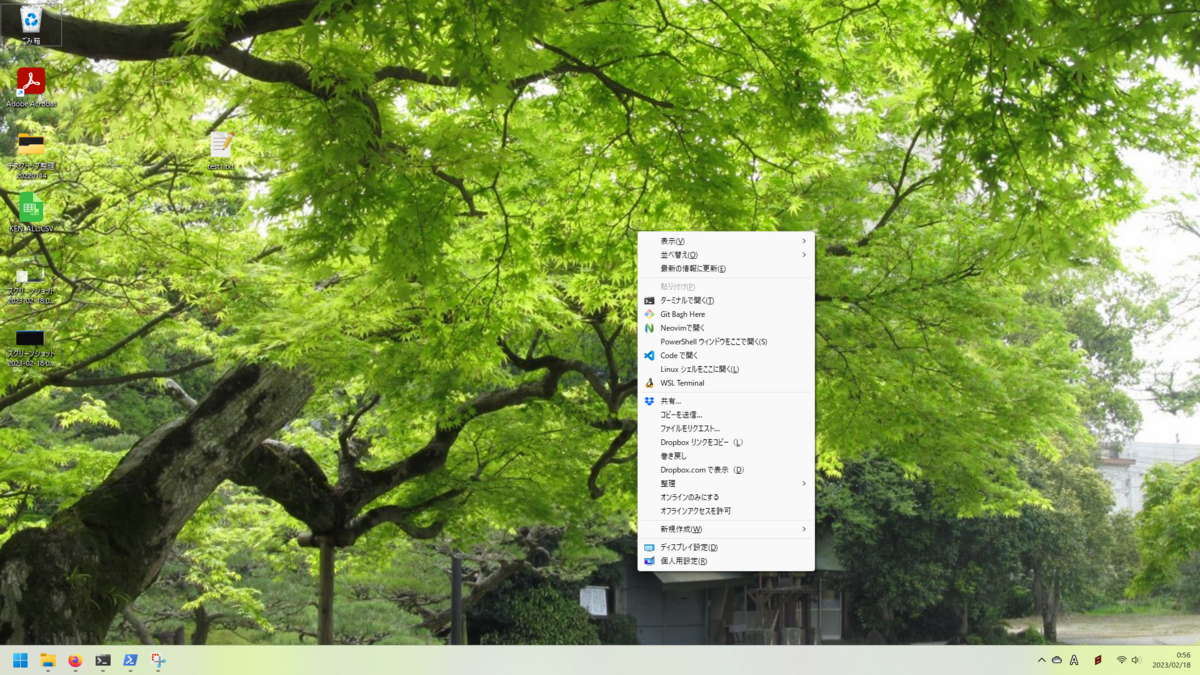
この中から「PowerShell ウィンドウをここで開く」の項目をクリックすると、デスクトップが操作対象となっている状態でPowerShellが開きます。ファイルをいろいろ扱いたい場合は、こちらの開き方がおすすめです。
小技集
PowerShellでは、内部の各コマンドのことを「コマンドレット」と称しています。コマンドレット名を打ち込むか、それとともに操作したいファイル名やオプションなどを打ち込むかすると、コマンドレットを実行できます。
ここからは、デスクトップを操作対象にした状態でPowerShellを開き、さらに、デスクトップ上に前回扱った郵便番号リストファイル「KEN_ALL.CSV」があることを前提とします。ファイルがない場合は、前回の記事を参考に入手してください。
指定したファイルを、既定のプログラム(Windowsによってその種類のファイルを開くよう関連付けされているプログラム)で開く
Invoke-Item KEN_ALL.CSV
Invoke-Item コマンドレットを利用し、その後に続けてファイル名を打ち込むと、関連付けられた既定のプログラムでファイルを開くことができます。ファイル1個だけですとあまり面白くありませんが、ワイルドカード(アスタリスク * や疑問符 ? )を利用して複数のファイルを指定すると、ワイルドカード条件に一致するファイルをすべて一気に開くことができます。
指定したファイルから、指定した文字列を検索する
Select-String KEN_ALL.CSV -Pattern "小郡市" -Encoding Oem
Select-String コマンドレットを利用し、Patternオプションで指定した文字列を含む行を取り出すことができます。ひとつ注意が必要なのは、KEN_ALL.CSVファイルはShift_JISエンコーディングで作成されているため、単にファイル名と検索文字列を指定するだけでは出力結果が文字化けしてしまいます。それを避けるため、Encodingオプションを利用して、ファイルのエンコーディングを明示的に指定します。日本語環境のWindowsでは、オプションを "Oem" に設定すると正しく表示されるはずです。

- ところで小郡市とは?
- 私の故郷にして本拠地です。
ファイルの内容を参照する
Get-Content KEN_ALL.CSV -TotalCount 5 -Encoding Oem
Get-Content コマンドレットを利用すると、指定したファイルを読み込んで表示できます。オプションを指定することにより、たとえば指定の行数だけ表示するようなこともできます。
- TotalCount オプション:ファイルの先頭から指定した行だけ取り出して出力します。
- Last オプション:ファイルの末尾から指定した行だけ取り出して出力します。
次回予告
前回の案内通り、Pythonで郵便番号リストをもう少しいじりましょう。
ツイ廃私がこの先生きのこるには
一時代の終わり
Twitter社の規約が(こっそりと)改訂され、「Twiiter公式クライアントアプリの代わりになるようなアプリ」について、Twitter APIの利用を制限する旨正式に発表されました。いろいろと場当たり的というか、本来望ましい手順を経ずに適当にやるあたり、諸君らは本当にまともに運営されている会社なのかと無職(広義)ながら疑問に思うところですが……まともな運営ならメチャクチャな機能をリリースしたり、恣意的に過ぎるツイート表示操作をしたり、大量に採用したりクビにしたりしない? その通り!
この規約改訂により制限(排除)されるアプリは、TLの閲覧とツイートがともに提供され、しかもそのスタイルが公式クライアントアプリに似たような振る舞いをするアプリであり、単にTLを取得するだけ、あるいは定型文を投稿するだけのようなアプリは従来通りAPIを利用したTwitterへのアクセスが可能であるとされています。
考えられる理由の憶測
おそらく本当の理由はリークでもない限り表には出てこないと思いますので、適当に憶測で書き連ねておくとします。
収益的観点で見ると、利用者全員に対して広告(プロモーションツイート)を表示させたい、正確にはそのようにしたと対外的に説明できる状況にして、「貴社のプロモーションツイートはターゲットユーザ全員に届いております!」としたいのではないかと思いました。サードパーティクライアントアプリによるTL閲覧や投稿においてはAPIの仕様上プロモーションツイートが配信されないため、スポンサーから「実際のところウチのプロモーションはどのくらい届いているのか? もっと増やせないのか?」と言われることもあったのではないかと推測しています。公式クライアントアプリに似た振る舞いをするアプリを排除するだけでも、その利用者の大部分は公式クライアントアプリへ移行すると思われますので、「プロモーションがより届くようになりましたぞ、というわけで広告費このくらいお願いできないでしょうか……?」として収入増にもつなげられそうです。
技術的観点で見ると、Twitter社買収直後に社内ITエンジニアが大量に離職してしまったとあり、各種のインフラ運営維持が間に合わなくなっているのではないかと考えられます。たとえば上記のプロモーション配信については、公式クライアント風のサードパーティアプリに対してもプロモーション込みのデータを渡すようにするという策が考えられますが、そのためのAPIエンドポイントを開発実装する人間がいなくなってしまった可能性があります。また、今あるAPIエンドポイントを管理できる人も不足したため、API公開範囲を縮小してコスト軽減を図るのかもしれません。
しかし離れられないのであった!
こんのクソ青鳥に付き合っていられるか、あばよ!
……ともいかないのがツイ廃の悲しさ。その有り余る情報技術系への適応能力のため、クソみたいな公式クライアントアプリでも30分で順応できてしまいました。人間関係上も、Twitter上でだけ交流がある人々が多数いるため、それを捨ててしまうことはできません。こうしてツイ廃は生きていく……
フォロワーからの提案
ここで、知人フォロワーのツイートに目が行きました。「Twitter公式アプリに類似するクライアントアプリが禁止なら、コマンドラインを叩くタイプのクライアントならセーフやな?」
なるほど!
どうみても「公式みたいな気軽な操作ができない(対外公式声明)」ような自作クライアントならば許される。許された。許せ(命令形)。コマンドラインは我が主戦場であり、私のバイブル「Windows/Mac/UNIX すべてで20年動くプログラムはどう書くべきか」(Amazonでは品切れになっていました)でもシェルスクリプトだけで色々実現したクライアント「KOTORIOTOKO」が載っていたりします。つまり技術的には可能で、モチベーション的にもまさに今こうしたアプリを自分専用で作って動かす機運が高まっています。やろう。
![Windows/Mac/UNIX すべてで20年動くプログラムはどう書くべきか 一度書けばどこでも、ずっと使えるプログラムを待ち望んでいた人々へ贈る[シェルスクリプトレシピ集]](https://m.media-amazon.com/images/I/51FOu+cPK4L._SL500_.jpg "Windows/Mac/UNIX すべてで20年動くプログラムはどう書くべきか 一度書けばどこでも、ずっと使えるプログラムを待ち望んでいた人々へ贈る[シェルスクリプトレシピ集]")
テキストだけのターミナル画面に次々に表示されるツイート、必要があればそのツイートからWebに飛んで画像を見る、ツイートはコマンドラインにカタカタカタカタッ、ターンッ! これだ。各種の業務が一段落してまた一時の暇ができたので作ります。
Twitter社に艱難辛苦(大袈裟)を与えられながらも生きる道を考えるなど
Twitterサードパーティクライアントアプリの大量締め出し(数年ぶりn回目)
くそう、またやりやがった!(画像略)
歴戦のTwitterオタクや、公式ウェブサイトや公式クライアントアプリが使いにくいなーという人が利用するサードパーティクライアントアプリが、数年ぶりにまた締め出しを食らいました。金曜日の日本時間12時過ぎ、突如として「認証が必要です」とのメッセージが表示されて強制ログアウトさせられ、その後再認証を試みるも蹴られまくり、諦めて公式クライアントアプリに緊急避難する事態となりました。はじめは自分のアカウントが凍結されたことを疑いましたが、タイムラインの報告では多くの有名どころのアプリを使っていた人がことごとく同様の被害に遭っていたため、これはTwitter社が何らかの意図をもって実行したものと思われます。状況をみるに、APIの総アクセス数が多い(≒利用者が多い)アプリの認証トークンを利用したAPIアクセス権限を停止した可能性があります。
この件について、Twitter社は現時点では特に公式声明を発表していません。情報技術をかじる者として、Twitter社がやりそうな声明の内容は多少は推測がつきます。「APIサーバへの負荷を軽減しつつユーザ体験のさらなる向上を図るため云々」とか言えば、社会的にも突っ込みようがない見解となります。本当のところはわかりません。
私は比較的初期からサードパーティクライアントアプリを利用してきました。当時は新着ツイートを次々に配信するUserStream APIが提供されており、アプリを立ち上げて接続し、UserStreamをオンにするだけで新着ツイートが無限に流れてきていました。我らTwitter中毒者にとっては新しい情報が続々来るのは幸せスパイラルそのものです。パック酒でスパイラルをグングン回すバンドメンバーよりは肝臓の健康によく、目の健康に悪いです。私はPCではOpenTweenやJanetterを利用していました。そのAPIが廃止されたとき、パソコンではTweetDeck利用に移行しましたが、スマートフォンでは引き続きサードパーティクライアントを活用していました。SobaChaやTweetCaster、びよーんったー、近年では長きにわたりTwitPane+を愛用していました。しかしこのたび、TwitPane+が締め出されてしまい、途方に暮れています。せっかく今月のみかじめ料を払ったのに……(Twitter Blue)
実際、近年のTwitter社は新機能に対するAPIエンドポイントを用意せず、公式クライアントアプリを使うよう誘導していた節があります。代表的なものとしては、投票機能は表示するための情報を得ることができても投票作成・投票実施用エンドポイントが無いため、サードパーティクライアントアプリでは機能を実装したくてもできません。Twitterスペースもそうです。リアルタイムなプッシュ通知機能もAPIが存在しません。スペースはどうでもいいですが、投票機能やプッシュ通知は活用しているので、癪ではあるものの公式クライアントアプリを併用していました。公式アプリを使えと言われればツイ廃ですから順応できなくもありませんが、でもなんだか使いにくい、でも手が伸びて使ってしまう。くそう。
そうだ、アプリ、作ろう(ただし自分専用)
金を払った手前、Twitter社に無条件降伏するのは業腹なので、10年ぶりに思い立って自分専用のTwitterクライアントアプリを作ることにしました。昨年夏にAPIアクセス用の申請をしていて、認証トークンの発行は受けていたため、それを活用することにしました。まずは実験としてPythonスクリプトからの投稿を試し、無事成功しました。昔と比べると認証回りが強化されて、手順がだいぶ増えている感じです。
APIとして外部公開されているものを全部実装しようとすると非常に面倒なので、公式アプリだと使いにくい部分だけを実装することを目指します。具体的には
- ワンステップでの投稿(誤タップ防止機構つき)
- ハッシュタグの入力支援を自分好みに
- TLの表示を自分好みに
- via芸をやりたいので投稿元アプリを表示
あたりを考えています。保有端末がAndroid系とiPhone・iPad系と両方あるため、ウェブアプリの形式で作るつもりです。がんばります。このあたりもうまくいったらこのブログの連載にしてみようかなと思います。
文字だけで扱うコンピュータの世界(13):テキスト調理その1・郵便番号データのフィルタリング
承前
♪~(音楽)
ATK「きょうの料理」の時間です。今日はお手軽な一品として「郵便番号データのフィルタリング」を作りましょう。材料は次の4つです。
郵便番号データは、以下の過去記事を参考に入手してください。
テキストエディタはひとまずVisual Studio Codeにしておきましょう。Visual Studio Codeの設定は、「Python Visual Studio Code 設定」のような単語で検索するとよい情報が出てくるかもしれません。そしてPythonの環境構築は以下のPython情報サイト(公式と言っていい)を参考にしてください。……でも初っ端に「Pythonのインストール、必要ですか?」と書いてありますね。この点でこのサイトが素晴らしいことが分かります。いくらガイドがあるとはいえ環境構築は面倒なので、やみくもにインストールさせるのは自分も気が進みません。単にプログラミングを体験するのであれば、まず体験をすれば良いというのが私の持論です。ここからのことは初手でやると訳がわからなくなりますので、先に「ゼロからのPython入門講座」やっときますか。ではよろしゅう。
「もう入門したからはよ次やれ」
……本当にやりました? 人間不思議なもので、目で読むだけだと頭の中を素通りしてしまいます。世の中のあらゆることの学習にあたって、手で書くと覚えやすいという経験則があります。プログラムを紙に手で書くのは50年前に終わっていますので、ここはスマートにキーボードでプログラムを打ち込むところからやりましょう。するとなぜか覚えます。不思議なものです。
サンプルプログラム
ではいきなりですが、このプログラムを打ち込んでください。入門のところでさんざん手打ちしたと信じていますので、ここからはコピペでOKです。私はRuby派なので、下のプログラムはもしかしたらPython的でない書き方かもしれません。さらに、いろいろ説明を端折っていきなりヘンな書き方を多数投入しているので初学者には向きません。「ゼロからのPython入門講座」に戻ってください。
""" chapter13.py 郵便番号データから、指定した住所の郵便番号一覧を取り出して表示する。 """ with open('KEN_ALL.CSV') as f: for line in f: # 1行読み込んだデータを、カンマ記号で分けてリスト化する # その際、各フィールドの値を囲むダブルクォートを取り除く line_elements = line.replace('"', '').split(',') if line_elements[6] == '福岡県' and line_elements[7] == '小郡市': print("{} - {} {} {}".format(line_elements[2], line_elements[6], line_elements[7], line_elements[8]))
よくある質問(FAQ)
- 質問1 福岡県小郡市ってどこ?
- 回答1 私の故郷にして本拠地です。
よくわからない解説
どのような分野でも、一通りできるようになった段階では、初学者に教えることができないとされています。その理由のひとつは「一通りできるレベルでは、初学者がわからないことや、わからないところがわからない」点にあります。私は何にひっかかりがちかすべてを把握する免許皆伝覇王であると豪語したいところですが、あまりフカすと真の達人からボコられるのでやめます。
このプログラムは、郵便番号データファイルを開いて1行ずつ読み込みます。その際にカンマ記号でデータを区切って分け、さらにダブルクォートを取り除きます。その中から、6番目の列(最初の列は0番目です)に書かれている都道府県と、7番目の列に書かれている市区町村を調べ、条件に一致するものを取り出して画面に出力します。出力する項目は、郵便番号、都道府県、市区町村、市区町村名以下の地区・大字等地名です。
実行!
プログラムと、郵便番号データを同じフォルダに入れて、その画面で右クリックして、「Codeで開く」というのをクリックしてください。 環境構築が完了している Visual Studio Code であれば、次のような画面が出てきます。右上の横向き三角(再生ボタンみたいなもの)をクリックすると、プログラムが実行できます。


今日はとりあえずこのへんで
検索条件の都道府県や市区町村を変えて遊んでみてください。もし多少プログラミングに慣れていたら、検索条件の列の追加や変更をしてみてください。
次回はこの続きをもう少しやりますか。別な話題に行くかもしれません。
あ、お茶のこと忘れてた
八女茶は福岡県八女市で産出されるお茶です。全国的には玉露で名高いです。嬉野茶は佐賀県嬉野市の特産です。最近西九州新幹線が開業しましたので、嬉野温泉駅で下車して遊びに行ってみてください。日本茶については次の2冊を勧めておきます。私も美味しくお茶を淹れられるわけではありませんが、抽出温度に気を配ると良いそうです。

